
From Correctness to Recoverability
Shifting problems from generation to validation.

LLMs are going to commoditize code production. And when it does, the problem shifts to how do you validate whether that code is useful.
How do we check more code?
We have the usual suspects (unit tests, integration tests) but they share a flaw: they require writing more code to validate the code (and if LLMs write the tests too, we’re back where we started). We could add linters and static analysis to raise the quality bar. We could use stronger type systems to guarantee the absence of certain behaviours.
But most of these approaches still assume humans can define and enforce the right checks at authoring time and that simply doesn’t scale with generated code volume
What about changing how we review code?
Tools like CodeRabbit offer summaries and visual diagrams. Qodo shifts review into the IDE. Perhaps we only review code with the highest probability of bugs?
Bugs can be anywhere, and while risk-based review helps, it doesn’t eliminate the volume problem - it just reallocates attention.
Have we been here before?
Spreadsheets democratized programming for finance, planning, and analysis. They also created an endemic error problem that we’ve never really solved. Studies consistently find error rates of 20-90% in corporate spreadsheets. The Reinhart-Rogoff austerity paper had a spreadsheet error that influenced economic policy. Excel’s auto-formatting has corrupted decades of genomics research.
The spreadsheet suggests society can absorb a lot of silent failure if the (perceived?) productivity gains are large enough.
But the analogy isn’t quite right. Spreadsheet errors mostly hurt the organization that creates them. Software has broader and faster externalities in time, data and trust.
Then again, we’ve been absorbing software failure for decades. Anyone who’s lost work to a crash or watched a progress bar lie to them knows the baseline isn’t zero defects. The question is whether LLM-generated code changes the rate enough to cross some threshold; the difference between “software sometimes has bugs” and “most software is mostly wrong.”
And there’s a darker possibility: maybe we just won’t notice? The genomics errors persisted for years and the Reinhart-Rogoff example shaped policy before anyone checked. If LLM-generated bugs are subtle and distributed (a thousand small degradations rather than one spectacular crash) we might absorb them not because we decided to, but because we never saw them clearly enough to decide.
From correctness to recoverability?
Since the dawn of software, applications have shipped faster with lower standards. “Just update to the latest version” is already the mantra. AI-assisted development is just another accelerant.
Do bugs matter as much if they can be fixed ten times quicker? (assuming they aren’t show-stoppers!).
In this future, observability becomes a first-class citizen. You can instrument code without writing much code (e.g. metaprogramming for cross-cutting concerns or declarative instrumentation via metadata). OpenTelemetry gives you the analysis capability, and LLMs can generate fixes faster than humans.
At sufficient scale, even human-in-the-loop repair becomes the bottleneck, pushing systems toward automated remediation for anything below a certain impact threshold. The application becomes part of its own feedback loop, with an always-on agent fixing bugs as users find them..
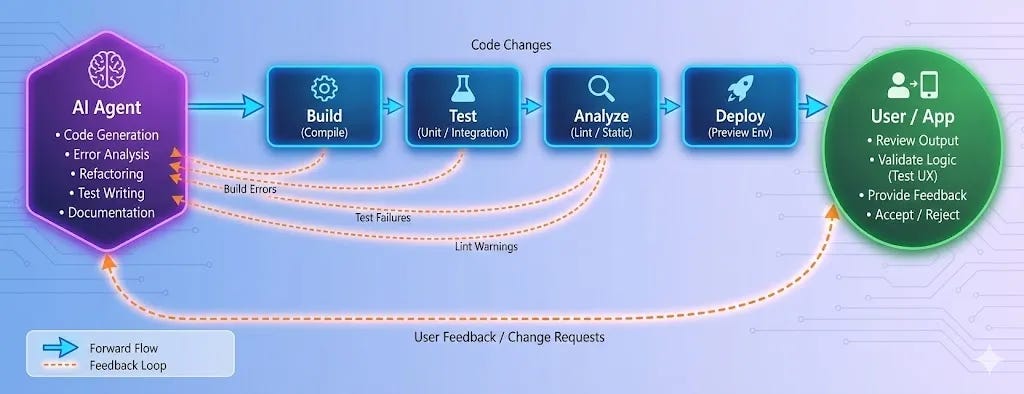
Self-healing code reads a bit like sci-fi optimism. We’re still some time from it, and we’ll need to find the right constraints (limiting the scope of patches, sandboxes, robust CI/CD pipelines, automatic rollback) but it doesn’t seem so far fetched at the end of 2025 as it did even six months ago.
Open Questions I don’t have the answers to:
What about persistent state? Self-healing is easy for pure functions, much harder for schemas, data corruption and dealing with side effects
What does accountability look like when no human understands the code or the fixes? What about provenance, auditability and liability?
If humans can’t review code fast enough, can they specify what should be done fast enough to guide self-healing? Is “can’t review” the same as “can’t even state desired behaviour”?
The shift from correctness to recoverability feels a likely direction of travel (did your child get a blockbuster game for Christmas and then have to wait multiple hours to get the latest patch?). Whether it’s desirable is a different question entirely.