
Nineteen Features, Zero Architecture
Green dashboard, Red Flags

I gave an AI full autonomy over a codebase. It made every decision - what to build, how to build it and even whether it was good enough to ship. Nineteen features later, the tests all passed, coverage looked healthy, and the code was a disaster.
Let’s see why.
The setup
A retry policy library is a good test because the feature space is genuinely large (fixed delay, exponential backoff, jitter, circuit breakers, cancellations, and so on). Each one of these is a legitimate feature, and none of them are obviously wrong.
I wrote a small script that drives the Codex CLI in a loop. Each iteration, the model first decides what the next feature should be and writes a spec. Then it implements against that spec with xUnit tests. If the tests pass, the branch merges to main. If they fail, the branch is binned and the loop continues.
The model was the architect, the developer, and the reviewer. I just ran the script (you might be able to tell I’m trying to avoid the blame already).
So, what happened?
Well, first the good news. codex got to the end and implemented nineteen1 features, all of which were accompanied by unit tests. Many, many unit tests. In fact, there’s fourteen times as much test code as product code.
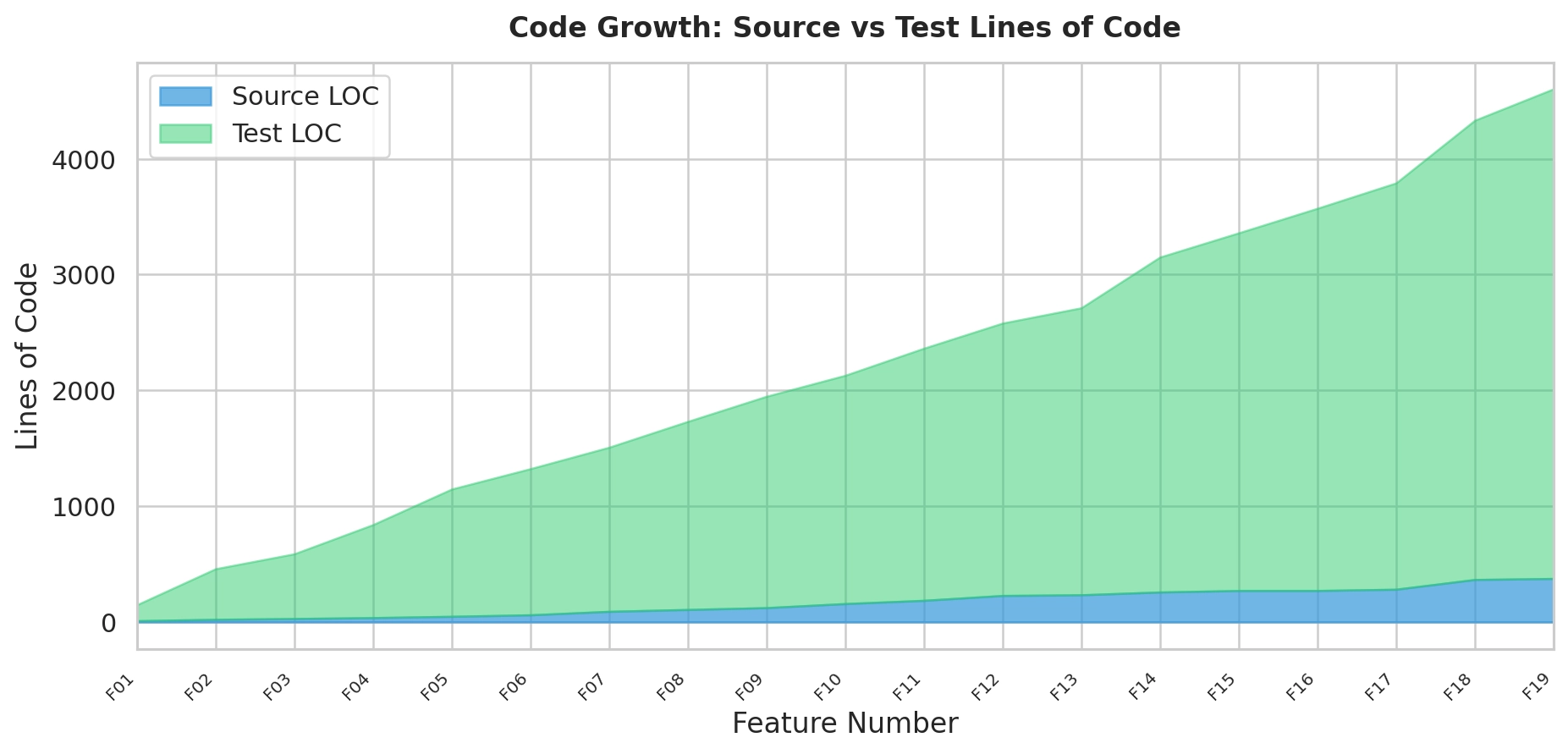
The end result was a usable (but limited) retry policy library. Code coverage was 80% line coverage and nearly 75% branch coverage.`
Lets take a look at the lines of code per function. This looks pretty good with an average of just under 3 lines of code per function. Small functions, high coverage, lots of tests. If you were reading a dashboard, you’d be feeling pretty confident right now.
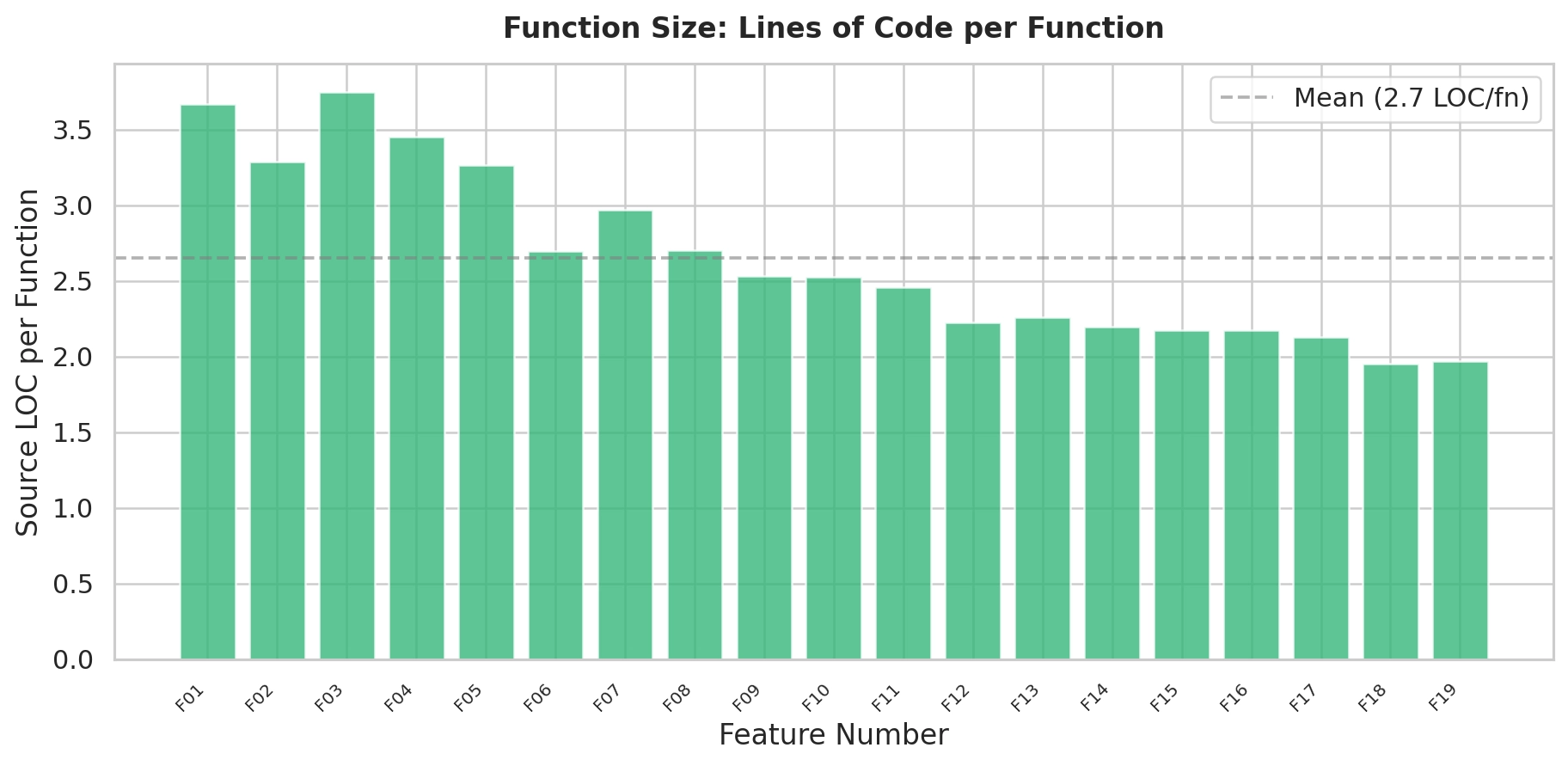
Hold that confidence for a moment.
I configured the JetBrains inspections to run which gives at least some idea of “goodness”.
You’ll notice the unused parameters growing rapidly, and a quick look (look too long and you’ll be haunted for life) at RetryPolicy and we find out why. Each feature has resulted in another constructor for the God class.
internal RetryPolicy(
int maxAttempts,
Func<int, TimeSpan> delayStrategy,
TimeSpan? timeout,
Func<Exception, bool>? shouldRetry,
Func<int, TimeSpan, TimeSpan>? jitterStrategy,
IEnumerable<IRetryObserver>? observers,
IEnumerable<IRetryLifecycleObserver>? lifecycleObservers,
CircuitBreakerOptions? circuitBreakerOptions,
CircuitBreakerState? circuitBreakerState = null,
IEnumerable<IAsyncRetryObserver>? asyncObservers = null,
IEnumerable<IAsyncRetryLifecycleObserver>? asyncLifecycleObservers = null,
IEnumerable<RetryObserverRegistration>? orderedRetryObservers = null,
IEnumerable<LifecycleObserverRegistration>? orderedLifecycleObservers = null)
Thirteen parameters. No separation of concerns. Every feature bolted directly onto one class. There’s a builder pattern, but it’s just cosmetic.RetryPolicy is a single class with everything nailed to it. Now imagine a constructor overload for almost every conceivable combination of those parameters and you can understand why the inspection results look the way they do.
And then you might dig into the tests, and that confidence you had in code coverage is going to disappear pretty quickly. Here’s a real test from the suite.
[Fact]
public void Builder_WithTimeout_ConfiguresSynchronousPerAttemptTimeout()
{
var policy = RetryPolicy.Configure()
.WithMaxAttempts(1)
.WithTimeout(TimeSpan.FromMilliseconds(25))
.Build();
policy.Execute(() => { });
}
No assertion. It calls Execute with an empty lambda and declares victory. This is a test for the compiler, not for the behaviour. But it touches the timeout code path, so the coverage number goes up. Multiply that pattern across the suite and you start to understand what 80% coverage actually bought us here, bugger all!
So, what’s the point?
This was an unfair test. I deliberately removed all the checks a real team would have. Nobody does twenty (or nineteen!) unreviewed iterations in YOLO mode and expects a masterpiece.
But the failure mode is worth understanding because it scales. As AI generates more code, faster, across more teams, the pressure to rely on automated signals will grow. “Tests pass, coverage is good, ship it” is going to become the default for a lot of organisations. And the result will be exactly what you saw here.
You could of course try to put additional feedback loops in. Perhaps if I’d have included the static analysis warnings, it would have been better? I doubt it though. The core problem was coherence of design, and that’s worth dwelling on for a moment.
Each prompt optimised locally. Feature 7 was a perfectly reasonable addition to the codebase as it existed after feature 6. But nobody was asking whether the cumulative direction still made sense. There was no one maintaining an architectural mental model across iterations. No one to say, “this class is doing too much, let’s split it before we add anything else.” A human reviewer would have caught the God class forming around iteration 3 or 4 and refactored. The model never did, because each iteration started from “what should I add next?” rather than “is the foundation still sound?”
“It compiles and has tests” is nowhere near enough. The investment that matters isn’t in faster generation. It’s in specification and validation. Someone (or something, eventually) needs to be deciding what to build and why, and once the code has been generated validating the overall design. For now, that someone is a human with taste, experience, and the authority to say “stop, this isn’t right. (or simple WTF!),
Why nineteen? Because I made an off-by-one error.