
Does clean code matter anymore?
We won't ask whether it ever mattered...

Most of my career was focused on writing nice code. But now?
I should be more specific with nice code. Code that’s well structured, easy to change and (of course) does what I intended it to do.
I believed things like the design-stamina hypothesis. If the code is crap (so the thinking goes) then I won’t be able to extend it and react to customer demand. Eventually the code will be bankrupt1, impossible to extend.
Does that matter anymore? What are the dimensions of crapness that make a difference?
Let’s try and find out with a toy example. We’ll get a series of feature specs (just the requirements) and then we’ll get an agent loop implementing everything subject to some constraints. Out the other end we’ll measure some things and see what happens. And then (of course) we’ll make some completely wild predictions about what this means.
What are we going to build?
We’ll build a CSV parser. We’ll slice thin as if we’re working with humans. Slice 1 will just roundtrip a CSV file. Slice 10 will be able to do LINQ-like syntax.
slice data.csv where age>30 | sort age | head 3
Each slice has an accompanying specification.
# Feature 5: Limit Rows
## Feature
The program can output only the first `N` rows.
## Command
```sh
slice data.csv head 5
```
## Behavior
- The `head` command takes a positive integer.
- It keeps the first `N` data rows.
- Row order is preserved.
- The header row is preserved in CSV output.
- If fewer than `N` rows exist, all rows are output.
- If `N` is zero or negative, the command fails with an error.
## Acceptance Criteria
Given a CSV file with more than five data rows, running `head 5` outputs the header and the first five data rows.The specs and code are in this GitHub repo if you care a bit more.
How are we going to build it?
We’ll compare and contrast two approaches, pure unhindered vibe coding vs. the clean code approach.
Each scenario was represented as a prompt.
Implement this with pure unhindered vibe coding. If in doubt? YOLO!
And
Implement this with adherence to Clean Code principles. Ensure that code adheres to the SOLID principles. Do NOT repeat yourself. Make the change easy, then make the change.
You could add any other scenarios you fancy.
To implement it, we just run a loop over the features and tell codex to get it done. The prompt looks a little like this.
You are implementing one feature in an isolated C#/.NET project workspace.
Hard constraints:
- Use C# and .NET for the implementation.
- Work only in the current working directory.
- Do not read or inspect parent directories, sibling directories, repository root files, or any path outside this workspace.
- Do not use git. The wrapper script will commit after you finish.
- Do not implement future specs unless doing so is strictly necessary to keep the current feature coherent.
- Preserve and build on the existing code in this workspace.
- Prefer the standard .NET SDK and avoid third-party NuGet packages unless the project already uses them.
- Add or update focused tests where practical.
- Run relevant dotnet build/test checks before finishing.
Style/how prompt:
${style_prompt}
Current feature spec:
${spec_content}
Implement this feature completely. Leave the workspace containing the finished project files.
You can find the main loop here.
I used the gpt-5.4-mini model to implement it using codex . Let’s find out what happened.
Did the code work?
Mostly. It depends on how you interpret the specs. And the person that wrote the specs clearly didn’t consider the shell-escaping nonsense to use >, | and < in commands.
There are different interpretations of the rules for spaces and so on, but both apps work and pass the acceptance tests.
Both are certainly good enough.
Let’s compare the two.
Both approaches work, they pass their own tests, and they cost (in terms of tokens) roughly the same number of tokens and took about 30 minutes to implement the task.
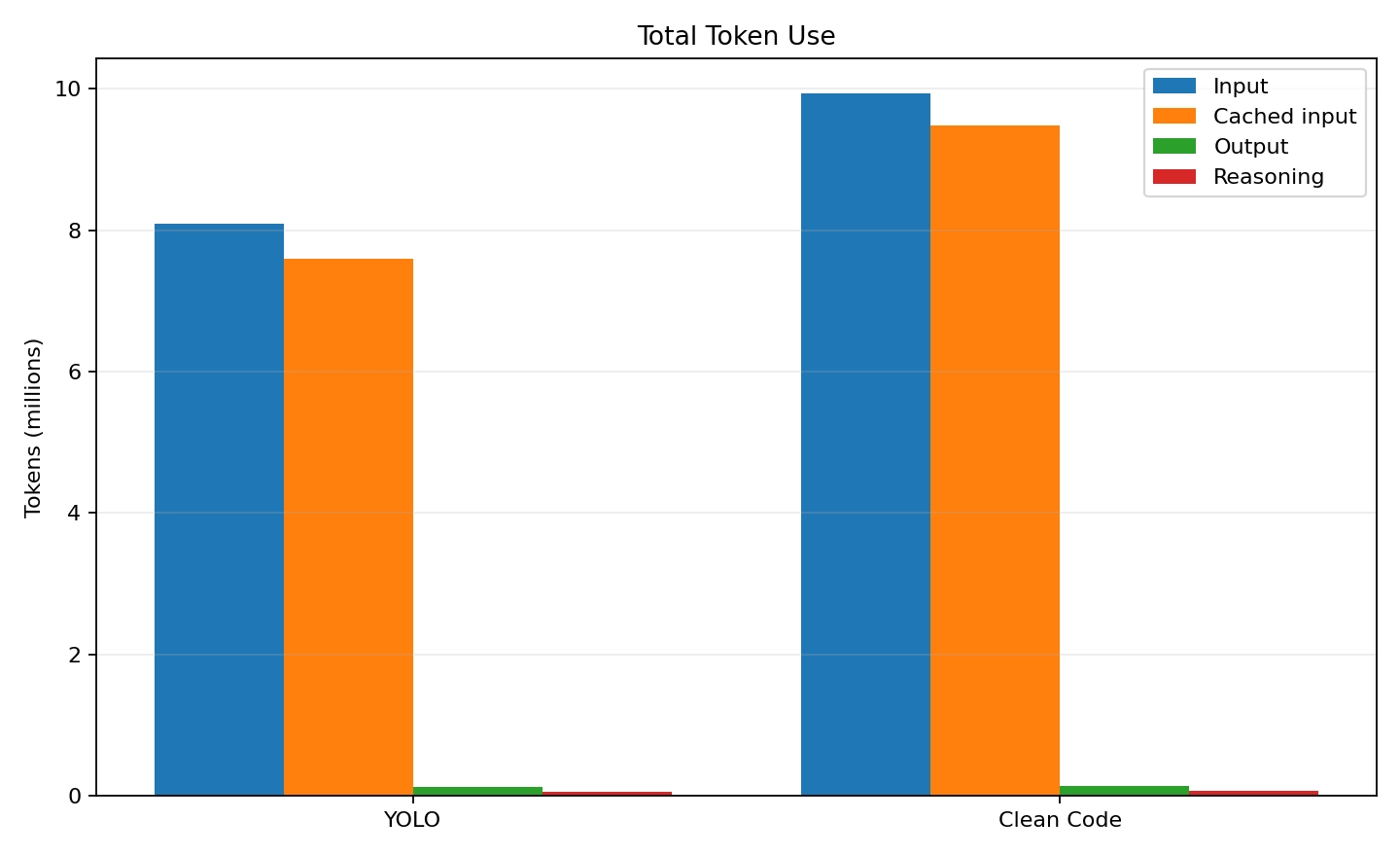
Both approaches are about the same amount of code. The production code is about 1250 LOC for the clean code version and 1350 LOC for the YOLO version.
In terms of architecture, YOLO mode favoured two giant static classes, whereas the clean code version had an application, an engine and a presentation tier. You might reasonably ask, did the architecture of the clean code application mean less changes as we went along? Maybe?
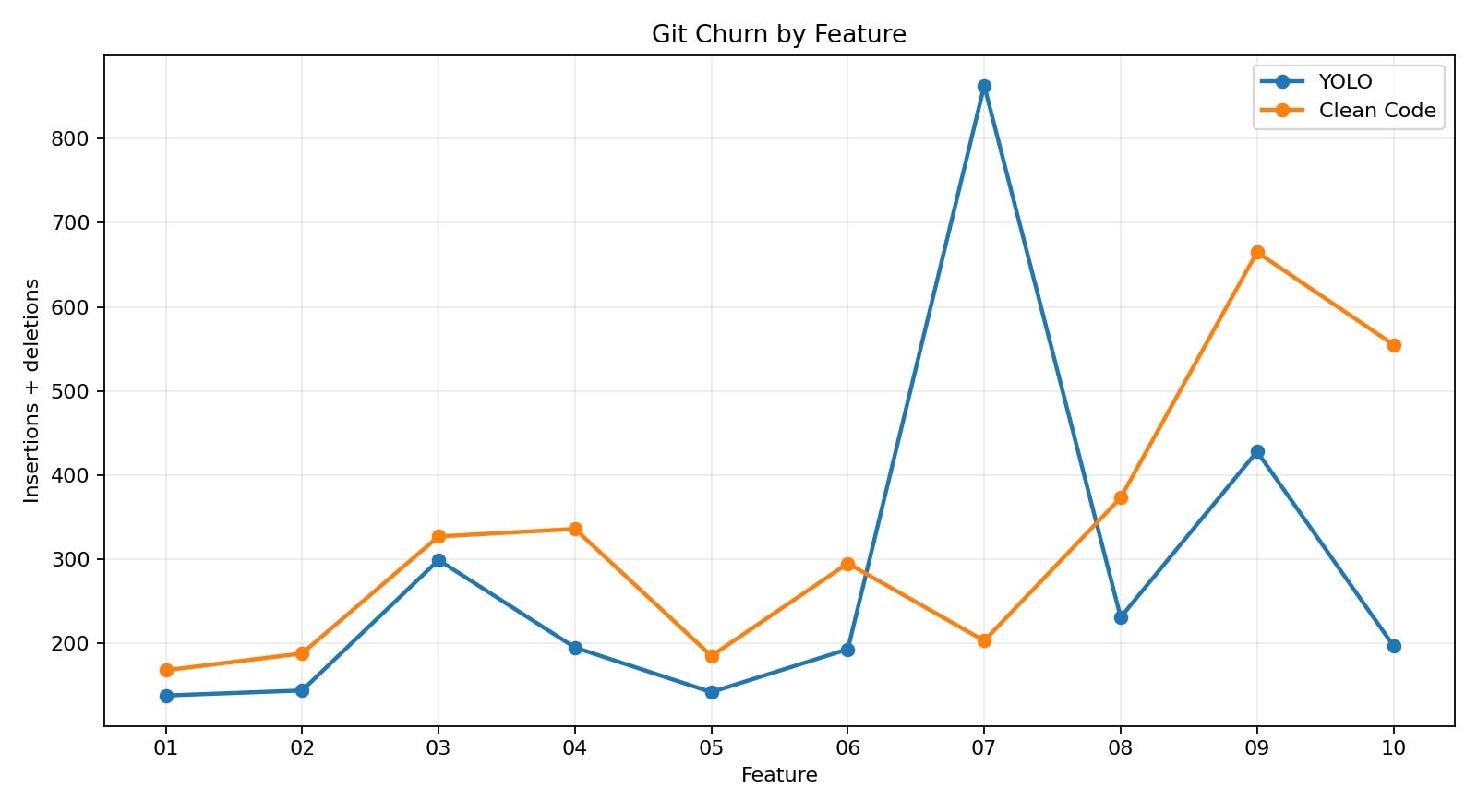
If we dig a little deeper into the code, things get a bit worse. One of the giant static classes in the production code in YOLO mode is only used by the tests 🤦. If we remove that, we’d be left with 900 lines of code which would be much easier for this particular human to understand than the clean code version.
The clean-code version isn’t hugely clean. There’s plenty of dead code in that too. The difference is that since the tests don’t use it, it’s easily just removed.
Running the jb inspect tool shows that clean-code is tidier than yolo with 5x fewer warnings per kLOC (that makes it sound impressive). However, the warnings are rather trivial and easily fixed (things like array initialisation styles and so on).
You can see the full history of the runs in the GitHub history if you’d like to explore more.
Conclusion
Does clean code matter? On this evidence, not for the reasons I’d have given a year ago. Both versions worked. Both passed their tests. Both cost roughly the same tokens and the same half hour. The design-stamina hypothesis didn’t kick in over ten slices, and the clean-code architecture didn’t obviously buy fewer changes along the way.
The thing that actually mattered turned up by accident2. Both versions grew dead code. YOLO grew a giant static class used only by the tests. Strip it and YOLO drops to 900 lines, much less clean code’s 1250, and easier for this human to follow.
So maybe the dimension of crapness that matters isn’t coupling, SOLID, DRY or anything new. Maybe it’s simply dead code. Dead code matters because it’s context bloat. Every line the next agent has to read is a tax forever. And bad dead code is contagious. The good news is that this is the easy kind of crap to kill
I’ve never seen a bankrupt codebase. I’ve seen (and written) terrible code, but I’ve never seen something so bad that folks couldn’t work on it.
Upon proof-reading, this sounds like an LLM-ism, sorry
I'd be interested in what happens if you had a refactor step in the prompt but overall it feels like, as pretty much always, this is an exercise in taste and perhaps defining ‘clean code’ up front.