
Fix your flaky tests first.
Before you break work into smaller chunks, have reliable (then fast) tests.

You've just joined a team with a classic dilemma: They have tests (good!), but they're slow and unreliable (bad!). Management wants smaller work batches for faster feedback, which makes sense (in theory…). But with tests that randomly fail and take ages to run, is smaller batches really the right approach? In this post, I'll show you why fixing your feedback loop reliability1 should be your first priority before tackling anything else.
Analysing Trade-offs
Let’s look at the trade-offs. You’ve got three variables:
Batch size (
b)Unreliable tests (we’ll use
pto represent the probability the tests pass)Slow tests (these tests take
Tto run)
Which one should we focus on? I wrote some code to draw some pictures and understand; it’s available here.
Let’s pretend I’ve got 100 units of work to do (each unit takes a unit of time too!). It takes 5 units to test my work, and if the tests fail, I start again. The good news is there is a 99% chance (based on historical knowledge) that the unit test pass for each unit of work.
What batch size should I work in? Let’s run a Monte-Carlo simulation based on these probabilities for 100 units of work. This is modelled as if the chance of failure increases as the batch size does (e.g. if I try to put n units of work through the tests, the probability of a pass reduces to p^n). If it’s not clear, this is a big assumption!
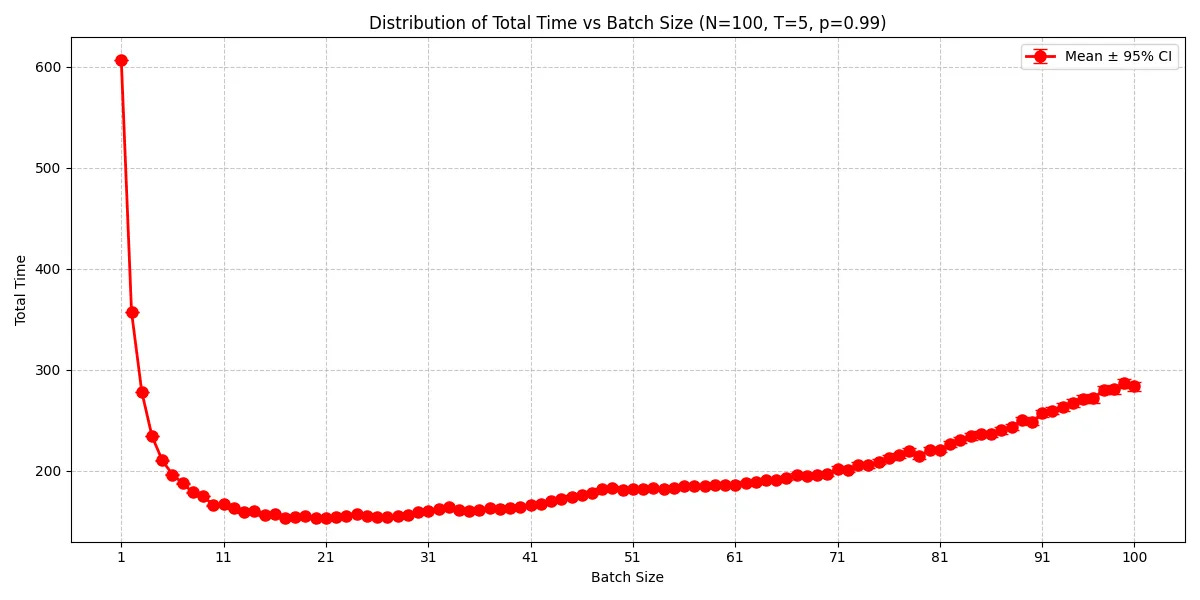
So, using the smallest batch size is a bad idea. That makes sense because you don’t amortize the test time. The total time starts to rise again once the batch size gets too big (0.99^b tends to zero as b gets bigger). Based on these parameters, you should work in batches of size 22 (or put another way, in this example you should spend 4x longer writing code than you do writing tests). Disclaimer: Not general-purpose advice.
Why is that?
We can calculate the expected time per task like this (the 1 is because we’ve just assumed a fixed unit of time).
This formula shows us the expected time per task, where we add the unit work time (1) to the test time (T) divided by batch size (b), all multiplied by the probability factor. As batch size increases, the test overhead per task decreases, but the probability of failure increases.
If you plot this graph, you’ll see it has the same shape as the one above. Which hopefully means my attempt at maths is going in the right direction.
Now, to find the optimum batch size we want to find where the derivative of the graph is zero (e.g. the flat spot at the bottom of the curve).
And after getting some serious help from AI and reminding myself about chain rules, product rules and all the stuff I haven’t used in yonks…
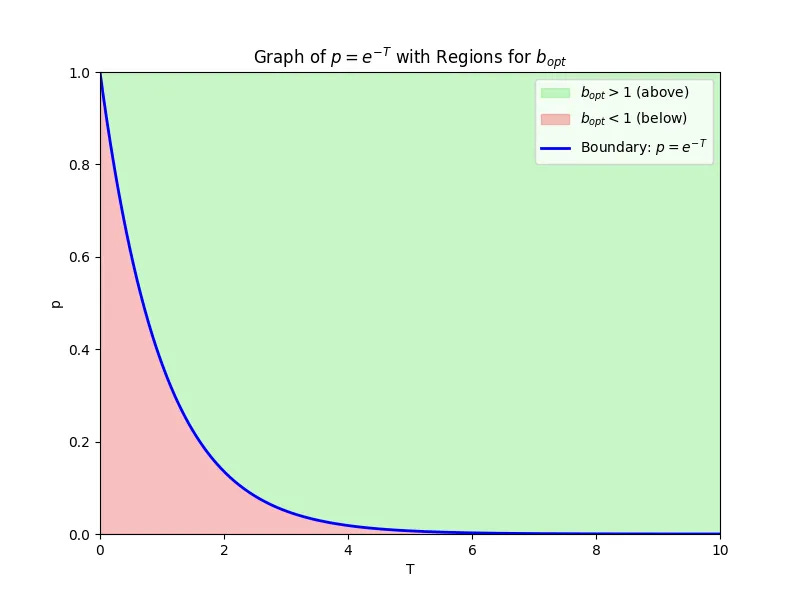
You want to reach the promised land of single piece flow. To do that, you’ll have to make this equation hold.
The good news is that’s true when p approaches 1 and the gate time is as low as possible as shown in the graph below.
That’s an awful lot of effort to state the bleeding obvious, right?
Why is this useful?
Should I make my tests faster? Or should I invest in making them more reliable? Well, we can do this now as we’ve got formulas to help us.
The graph below shows the impact on expected time for any particular probability and duration. If it’s blue, focusing on the probability of passing is the best you can do.
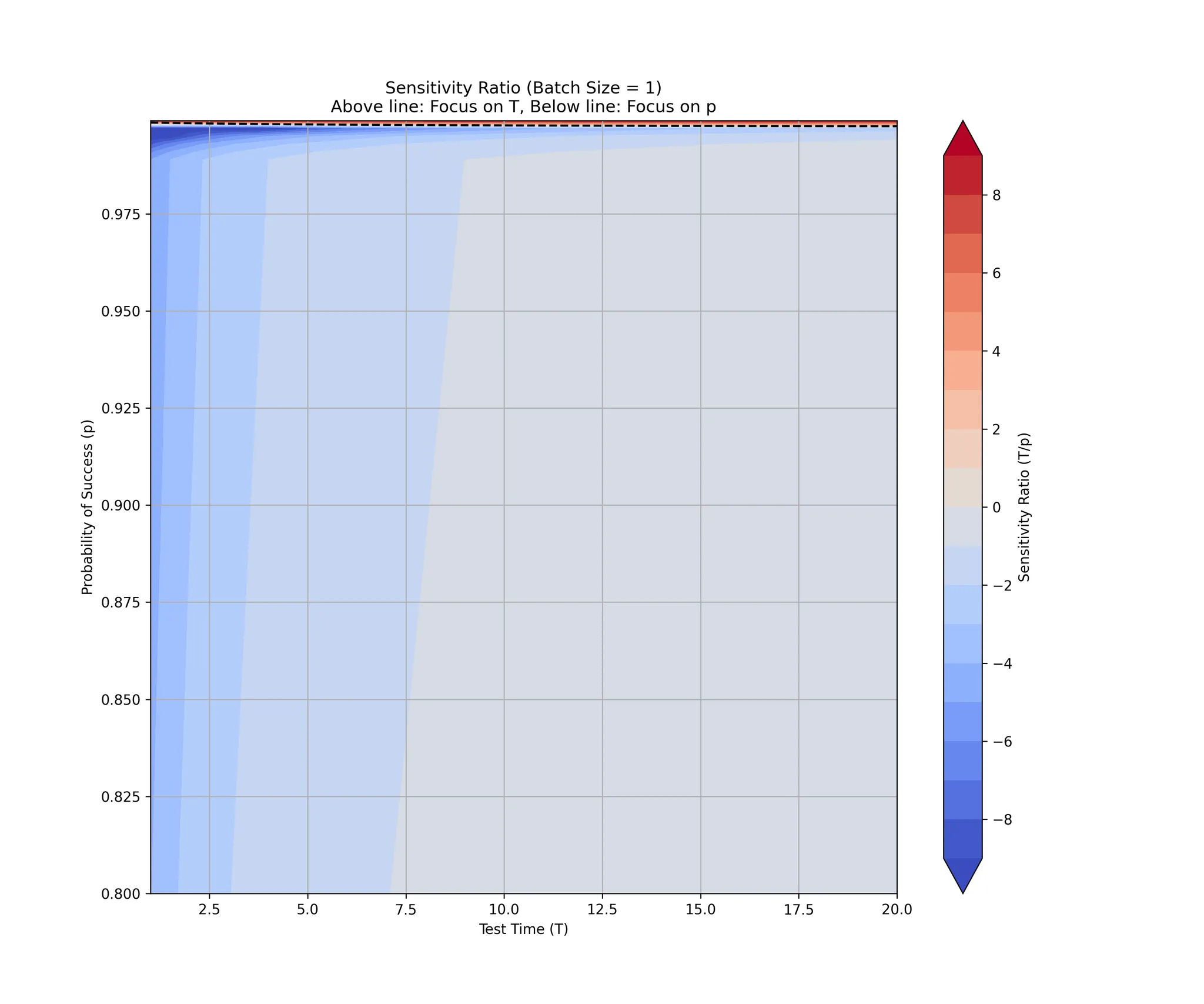
Focus on test-reliability. Flaky tests are worse than long running tests (at least in the limit!).
The limit is carrying a lot of weight there! Let’s imagine something a bit more bounded. You’ve got 100 units to do, and you’re working with a batch size of 1. Find where you are on here and if it’s blue fix the tests and if it’s red, make them run faster.
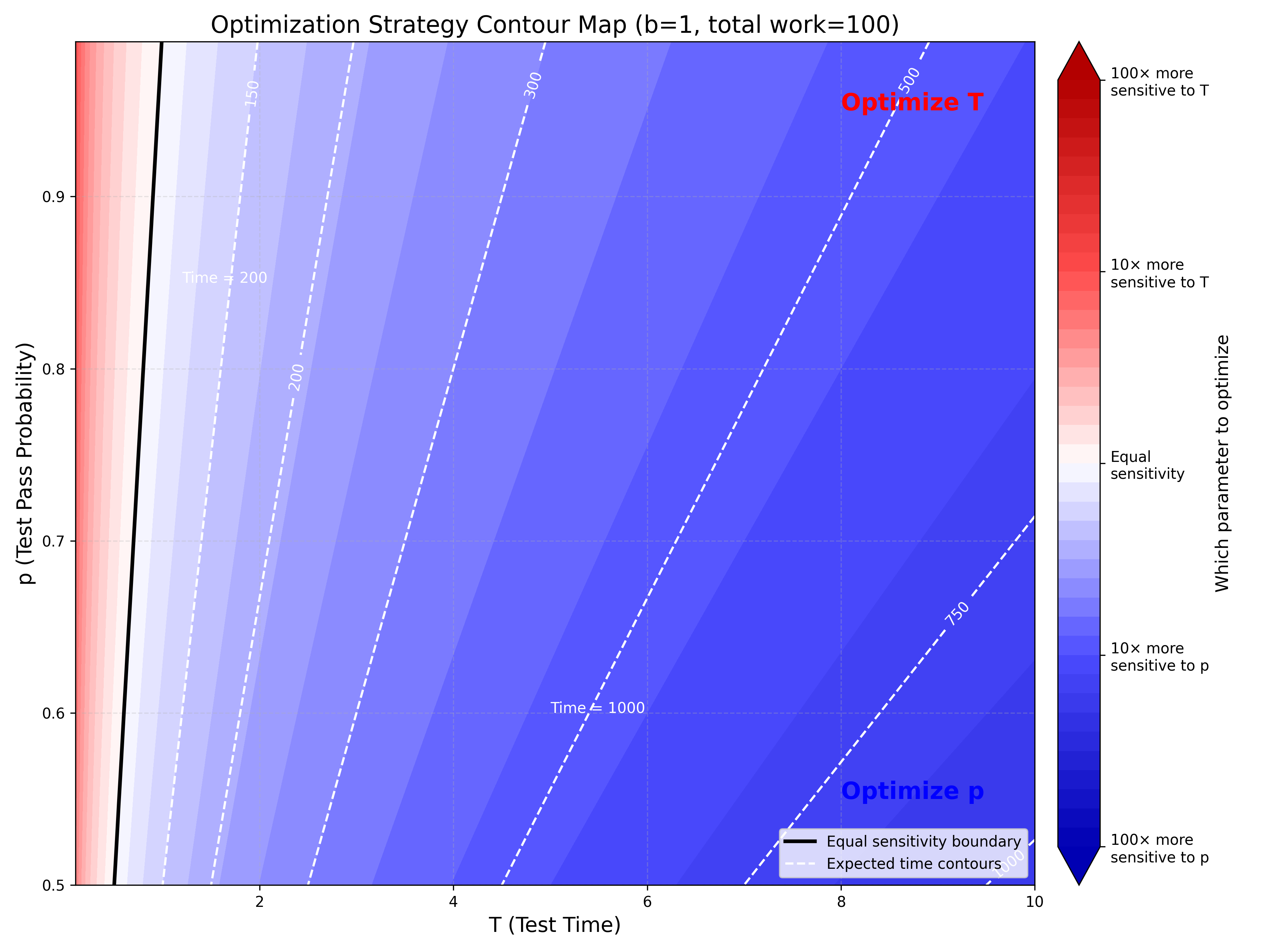
It’s still dominated by fixing the probability (unless running the tests takes less long that writing the feature).
Of course, this makes the assumption that you don’t just ignore the flaky tests and move onto the next stage. You wouldn’t do that would you?
Practical Takeaways
Reliability trumps speed - As we’ve seen, flaky tests hurt productivity more than slow tests. Focus on making tests pass consistently before optimizing for speed.
Batch size depends on context - While smaller batches generally provide faster feedback, there’s a sweet spot based on your specific test reliability and duration
The path to continuous delivery - To reach that nirvana of single-piece flow, work on reliability first, then optimize for speed.
Next time you join a team struggling with their development pipeline, remember this order of operations: Fix reliability first, then speed, then batch size. Your productivity (and sanity) will thank you.
In the future, we’ll explore want happens when we want to optimize for learning, not throughput.
With the set of assumptions that I’ve made that may or not be right!
why are the sensitivity graphs at the end using a batch size of 1? earlier you stated "using the smallest batch size is a bad idea" so why would our optimization strategy be guided by "a bad idea"
I'm having trouble understanding what a "batch" is supposed to mean in this context. What does it mean to run a batch of size `b` through the tests? I feel like this is probably an intentionally abstract term since what different disciplines test and how they test varies but having a concrete example would I think help me make sense of this better.